
Publication
Global Asset Management Review: Issue 4
Welcome to the third issue of Global Asset Management Review.

Global | Publication | May 2024
On 18 September 2023, the CMA published its Initial Report (Initial Report) on AI Foundation Models (FM), supplemented in April 2024 with the publication of its “Update Paper” focused on potential antitrust risks associated with FMs, a “Technical Update Report” providing more detail on the development on FMs (collectively the “Reports”) and a strategic update.
In the Initial Report, the Authority considered three levels of the AI FM value chain (although it focused mainly on the first two levels):
In the Technical Update Report, a new level was added to the AI FM value chain: AI release (where the CMA distinguishes between “closed source” and “open source”).
The Initial Report characterised FMs as large, general machine learning models trained on vast amounts of data, noting in the Technical Update Report that over 330 FMs have been released to date (although some have already become obsolete and have been replaced). The Reports acknowledge that, while some FMs have been released by established technology players (Google, Meta, Microsoft and NVIDIA), new entrants include OpenAI, Anthropic, Stability AI, Midjourney, Mistral’s Mixtral 8x7b, Cohere’s Aya. Further, the Update Paper notes that, while OpenAI’s GPT-4 is widely regarded as a leading FM, open-source FMs remain an important source of competition and innovation.
The Initial Report addressed training, fine-tuning and deployment of FMs that are deployed in user-facing applications (including direct deployment, access through APIs (AI-as-a-Service) or building plug-ins to work with FM applications). In the context of deployment, the Initial Report differentiated between “open source” FM models (that are freely shared, enabling other RM developers to build on them, such as the UAE Technology Innovation Institute’s Falcon model), models that are available (in that licensing restrictions limit commercial use, like the license required for Llama-2 if the app/service into which it is deployed has more than 700 million monthly users), and “closed source” models that are not publicly shared and are either only used by the developer itself (e.g., BloombergGPT) or licensed for use through APIs (e.g., OpenAI’s GPT-3). The Technical Update Report makes this distinction higher up the value chain (before model “fine-tuning”).
The CMA views FM development, training and deployment as being structured as follows:
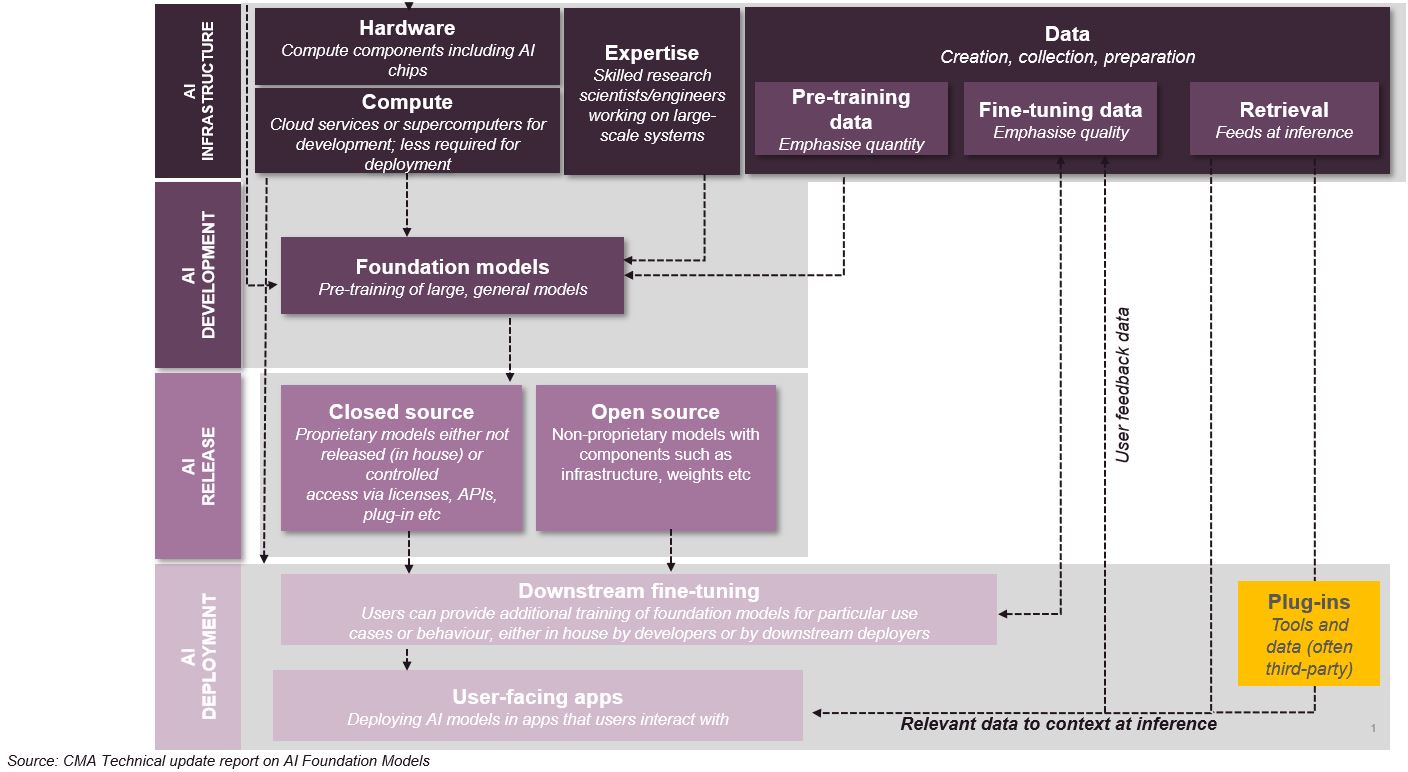
In the Initial Report, the CMA identified three key issues that it believes will determine whether development of FMs will remain competitive or whether only a handful of leading models will be created and maintained, namely access to data, access to compute power and first mover advantage. It has built on this in the Reports. In addition to these issues, the CMA also considers:
We look at these five potential issues in turn below:
Access to Data
The Initial Report noted that, while some FMs were pre-trained using only publicly available data (e.g., Meta’s Llama 2 and Stability AI’s Stable Diffusion), others have used non-public data (e.g., academic journals, image repositories and content websites). However, it then concluded that “freely available data may be fully exploited” (or grow at a slow rate), such that FM developers without access to proprietary data that they produce themselves (i.e., because they are not vertically integrated or active in related markets) will have to purchase it, thereby increasing their costs. This appears to ignore the fact that licensing of third-party data to train AI models already appears to be common. OpenAI, for example, has entered (or is seeking to enter) into multiple (non-exclusive) licenses in 2024),1 and a number of entities with data (including Reddit) have publicly stated that they are entering into (non-exclusive) licenses with multiple AI model developers.2
Further, it is not clear how the CMA has concluded that, despite the exponential growth of the Internet, scraping will not produce broad and deep data sets for FM training. It has moreover not considered that certain third-party sources, like image repositories, are particularly relevant for Image Generative AI models such that developers are likely to seek to license their content regardless of their proprietary data sources (rather than their use reflecting a dearth of public data for FM training). Nor does it consider the potential impact of data portability rights under the EU Digital Markets Act (DMA) and EU Data Act (DA) for example, that have the potential to increase the amount of user-generated data that might be available to FM developers. As a result, it is not clear why the CMA is suggesting that the viability of synthetic data is central to training of new FMs or that proprietary data would become less available or more expensive, thereby risking tipping of FM development to vertically integrated developers.
Access to Computing Power
The CMA rightly notes that popular open-source FMs have tens of billions of parameters, so that they need access to large, distributed computing. Having referenced compute costs that range between $4 million (Meta’s LLaMA) and $100 million (Megatron-Turing NLG), the CMA states that it has heard that FM developers with existing arrangements with computing providers are more likely to get access to the computing power that they need. However, it does not suggest that cloud infrastructure providers have refused (or are likely to refuse) access to computing – the Ofcom cloud report which it references considered issues relating to switching and multi-homing, not excessive pricing or refusals to supply. As a result, while the CMA is correct that competitive FM development requires access to computing power on fair commercial terms, without undue restrictions, it does not appear that such access is not being provided.
Beyond this, it is important to note that FM developers are not limited to using compute provided by cloud providers. As both the Update Paper and Technical Update Report acknowledge, since the publication of the Initial Report, new AI accelerator chips have been released or announced. Additional supply of AI chips facilitates FM developers deploying their own compute resources and alleviates (at least in part) the difficulties that some FM developers had experienced in securing supply of AI accelerator chips. This may also lead to smaller FM developers concluding that they do not need partnerships with major cloud providers, something that the Technical Update Report identified as potentially enabling large partners to shape FM-related markets in their own interests.
However, it is important to flag that the Technical Update Report notes that new model architectures that reduce the memory and compute requirements of FMs are being developed.
Despite these developments and the fact that the study underpinning the Technical Update Report is on-going, the CMA notes that compute might be an input that is prioritised for investigation under the new UK Digital Markets, Competition and Consumers Bill (DMCC) powers.
In short, the Update Paper notes that strong players controlling these inputs could restrict access to them, both preventing the development of competitive FMs and protecting their position in related markets, such as search. Access to key inputs might also be limited by consolidation across multiple levels of the FM value chain, as noted in the Technical Update Report.
First mover advantage
While early movers in certain markets have enjoyed advantages, it is not yet clear whether prominence and brand recognition (both cited by the CMA) are crucial in relation to FMs. We do not yet know whether or how the success of directly deployed FMs or FMs deployed to improve existing or new services will turn on prominence and brand recognition. As the CMA itself notes, several of the FMs developed to date are now obsolete, and it seems unlikely that FM used as an input will be successful largely because of prominence or brand recognition. Further, it is not clear that new entrant FM developers will be unable to access funding – as recently as July 2023, start-up AI developers were raising hundreds of millions in funding in a matter of weeks. Finally, the CMA notes that “feedback loops” have the potential to benefit FM developers that are active in other markets. However, this point does not appear to be related to the timing of entry; rather, it appears to be another limb of the “access to data” concerns addressed above.
The CMA’s analysis of FM development concludes by identifying five “key uncertainties” framed as having the potential to make it harder for “some firms” to compete, thereby stifling innovation and limiting diversity:
Effective Choice and the Ability to Switch
The CMA’s Initial Report made it clear that there are currently a broad range of models for deploying FMs beyond developing an FM from scratch (e.g., Bloomberg and Adobe):
FM service developers told the CMA that it is relatively easy to switch between models (and FMs). Despite this, the CMA states that it is uncertain whether such switching will remain easy and affordable since it is not clear that the market for development of FMs is competitive. Displaying a rather circular logic, the Report then notes that competition in FM development will be more effective if FM service developers are able to easily switch between FMs.
The Initial Report focused on consumers potentially preferring to be able to access an “ecosystem” of FM services and non-FM services at once (e.g., integrating productivity software and operating systems), enjoying the convenience of having a single, integrated ecosystem that can learn about the user from engagement with other services to customise services integrating FM. While the CMA acknowledges that such customisation will improve the user experience, it notes that consumers will only be able to switch to a rival provider if they do not lose the customisation benefit, creating the potential for lock-in.
In this context, the Report notes the importance of data portability. Of course, since regulation is being introduced in several jurisdictions that will enable such portability (e.g., DMCC in the UK, DMA in the EU), data portability is something of a red herring. The CMA seems to doubt that FM services will have access to the necessary FM inputs (despite the market feedback to the contrary). Beyond that, the CMA seems to be hinting that conventional “interoperability” will not be sufficient to enable competition between and with “portfolios” (or “ecosystems”) of FM services, although it did not tease this out of the various references in the Initial Report to ecosystems, the impact of vertical-integration and leveraging of market power in related markets.
The Update Paper, however, does this to some degree, expressing concern that, while businesses and customers should be able to exercise free choice over which FM services they use, that choice might be limited by technical integration of FMs into incumbent firms’ ecosystems of products and services. While the CMA acknowledges that such integration can bring benefits, it is concerned that major players could make it harder for rival FMs or downstream applications to compete. In particular, the CMA warns against pre-installation, technical bundling, and restrictions on accessibility, integration and compatibility. The Portuguese Competition Authority (AdC) raised similar concerns in its November 2023 report. In addition to access restrictions, the AdC also identified leveraging strategies (particularly tying and self-preferencing) as “more concerning” practices if carried out by a firm with a dominant position.
Vertical Integration and Partnerships
The CMA’s Initial Report noted that there was already significant vertical integration, from the cloud layer through FMs to FM services, and a number of partnerships. Strangely, it characterises platform services, like Amazon Bedrock (offering customers access to Amazon’s own FMs and Anthropic and Stability AI FMs) as “integrated”, rather than as an illustration of the broad access being provided to FMs (which the Report itself notes is the case in its earlier discussion of FMs).
The Initial Report noted the potential for a vertically integrated FM player to impose restrictions that impede competition downstream in FM services, despite noting (in the next section) the strong incentives of FM developers to have their models used widely to facilitate ongoing training of those models. The Update Paper raises particular concerns over partnerships between major players and FMs developers. The CMA warns that it is vigilant against the possibility that “incumbents” may try to use partnerships and investments to eliminate competitive threats, “even where it is uncertain whether those threats will materialise”. The CMA appears to be concerned that some partnerships might fall within its Enterprise Act jurisdiction.
In this context, the Update Paper identifies factors that might raise concerns in the context of partnerships:
Data Feedback Effects
The CMA takes the uncontroversial view that the greater the feedback effects, the faster FM services will be able to improve their services. However, it then blurs the distinction between improvements to FMs and downstream FM services to imply that vertically integrated FM and FM service providers will enjoy a competitive advantage, ignoring the incentives of all FM providers to have their models deployed into a broad cross section of FM services, precisely to increase the relevant feedback data. It may be that the CMA’s real concern is “cross-use” (to borrow from the DMA) of data between FMs and multiple FM services, but it does not say that.
It appears that the CMA’s preliminary view is that significant data feedback effects, a lack of real consumer choice, and vertical integration and partnerships create a risk of anticompetitive effects in FM services markets that warrants further consideration.
The CMA’s study is yet to be concluded. However, it is noteworthy how its approach slightly diverges from that of other authorities, such as the AdC or the European Commission (EC). Indeed, the AdC provides a detailed description of the competitive dynamics occurring in connection with FM development and deployment. A similar approach is expected to be taken by the EC. In its January 2024 call for contributions on “competition in virtual worlds and generative AI”, it sought input on different issues, such as barriers to entry, role of data and positioning of “incumbents” in the development and deployment of FMs. Interestingly, the EC also asked whether generative AI will require the EU antitrust rules to adapt.
Interestingly, the Technical Report clearly identifies the market power held by incumbent firms as a threat to fair, open and effective competition. However, in the section on competition concerns, it recalls what is acknowledged by the Update Paper and identifies, for the reasons described above, partnerships as posing antitrust risks.
The CMA has proposed the following “guiding principles” to ensure competitive development and deployment of FMs, noting that they could be undermined by M&A activity, “leading” players blocking innovation, restrictions on switching between and multi-homing on FM providers, ecosystems unduly restricting choice and interoperability, and tying or bundling:

Publication
Welcome to the third issue of Global Asset Management Review.
Publication
On 13 November 2025, the European Parliament adopted (subject to certain amendments) the substantive Omnibus Directive which was proposed by the European Commission on 26 February 2025 (see our previous briefing here). On 16 December 2025, the European Parliament adopted further proposed amendments.
Subscribe and stay up to date with the latest legal news, information and events . . .
© Norton Rose Fulbright LLP 2025
